在計算機操作系統的核心機制中,進程同步是確保多個進程或線程有序、協調地訪問共享資源,從而維持系統數據一致性與執行正確性的關鍵技術。與之緊密相關的計算機系統服務,則為進程的運行提供了基礎環境與支持。本文將作為復習筆記,梳理這兩部分的核心概念與原理。
一、進程同步的必要性與核心問題
在多道程序設計的現代操作系統中,多個進程并發執行是常態。當這些進程需要訪問共同的資源(如共享內存區、文件、硬件設備)或進行通信時,如果沒有恰當的協調機制,就會引發一系列問題,其中最典型的是 “競爭條件”。
- 競爭條件:多個進程并發讀寫某些共享數據,而最終的結果取決于進程執行的精確時序(一種不確定性狀態)。這往往導致數據不一致或程序運行錯誤。
- 臨界區問題:為了避免競爭條件,需要確保進程互斥地訪問共享資源。進程中訪問共享資源的那段代碼被稱為臨界區。任何時刻只允許一個進程進入其臨界區。一個好的同步解決方案必須滿足:
- 互斥:任何時候至多一個進程可在其臨界區內。
- 前進(空閑讓進):如果沒有進程在臨界區內,且有進程希望進入,那么應能盡快決定由哪個進程進入。
- 有限等待:一個進程從提出進入請求到被允許進入,其等待時間必須是有限的。
二、進程同步的主要機制
操作系統和編程語言提供了多種機制來實現進程同步。
- 軟件方法(算法):如Peterson算法、Dekker算法等。這些算法通過共享變量來協調進程,但通常只適用于兩個進程,且依賴于忙等待(自旋),效率較低。
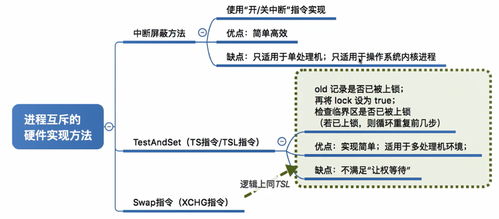
- 硬件方法:通過特殊的原子指令來保證互斥,例如:
- Test-and-Set指令:原子性地讀取并修改內存單元的值。
* Swap指令:原子性地交換兩個字的內容。
硬件方法簡單有效,但同樣可能涉及忙等待,且對編程者要求較高。
- 高級抽象機制(最常用):
- 信號量:由Dijkstra提出,是一種整型變量,只能通過兩個原子操作
P(或wait)和V(或signal)來訪問。信號量分為:
- 計數信號量:值域不受限,用于管理多個同類資源。
* 二進制信號量/互斥鎖:值只能為0或1,用于實現互斥。
信號量功能強大,可用于解決互斥和同步(如生產者-消費者問題、讀者-寫者問題)等多種經典問題。
- 管程:一種高級同步原語,將共享變量及其操作封裝在一個模塊中,管程內的過程在同一時刻僅允許一個進程活躍。管程通過條件變量及其
wait和signal操作來管理進程的阻塞與喚醒,比信號量更易于保證正確性。
三、計算機系統服務:進程運行的支撐平臺
進程同步機制的有效運行,離不開操作系統提供的一系列底層系統服務。這些服務是操作系統內核的核心功能,為所有用戶進程和應用軟件提供基礎支持。主要系統服務包括:
- 進程管理服務:
- 進程創建與終止:提供
fork(),exec(),exit()等系統調用。
- 進程調度:決定哪個就緒進程獲得CPU使用權。
- 進程同步與通信:提供前述的信號量、消息隊列、共享內存等機制的系統調用接口。
- 內存管理服務:
- 為進程分配和回收內存空間。
- 實現虛擬內存、分頁、分段等,為每個進程提供獨立的地址空間,這是進程隔離和安全的基礎。
- 文件系統服務:
- 提供文件的創建、讀寫、刪除、目錄管理等操作。
- 管理磁盤空間,實現數據的持久化存儲。
- 設備管理服務:
- 抽象硬件設備,提供統一的設備驅動接口。
- 處理設備的I/O請求,管理緩沖區。
- 保護與安全服務:
- 實施訪問控制,確保進程只能訪問其被授權的資源。
- 提供用戶認證、權限管理等安全機制。
四、聯系與
進程同步是并發編程中的核心挑戰,它依賴于操作系統提供的系統服務(特別是進程管理和通信服務)來實現其機制。例如,一個P操作在底層可能涉及將當前進程狀態改為阻塞,并將其放入信號量的等待隊列,這需要進程調度和內核數據結構的支持。
反之,系統服務的穩定、高效運行,也必須處理好其內部可能存在的并發訪問問題(例如,內核數據結構本身的同步),這同樣需要用到進程同步技術。因此,理解進程同步是深入理解操作系統內核如何工作、如何提供可靠服務的關鍵。在復習時,應結合經典同步問題(生產者-消費者、哲學家就餐等),通過偽代碼深刻理解信號量和管程的應用,并明晰這些高層抽象是如何構建在底層系統服務之上的。